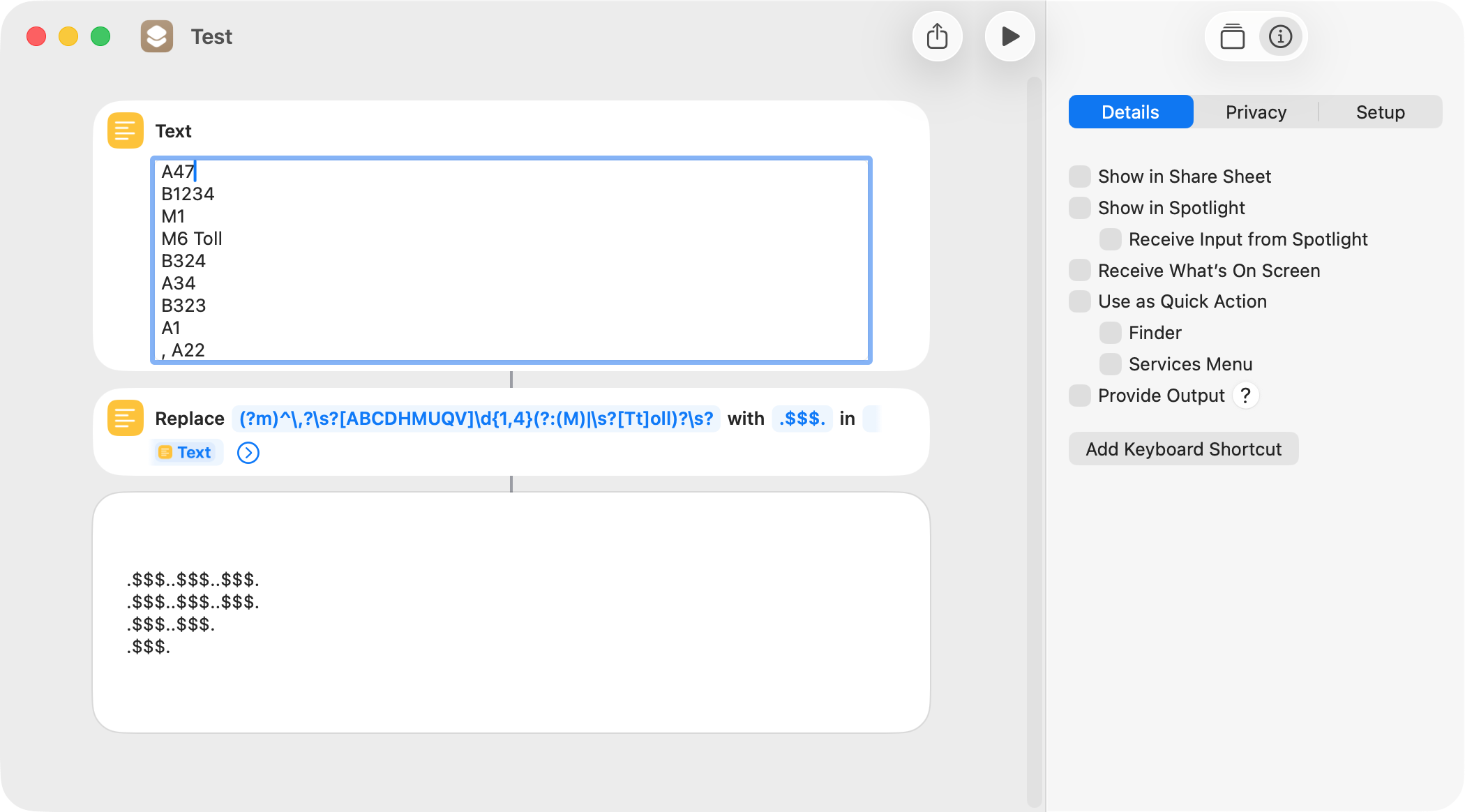
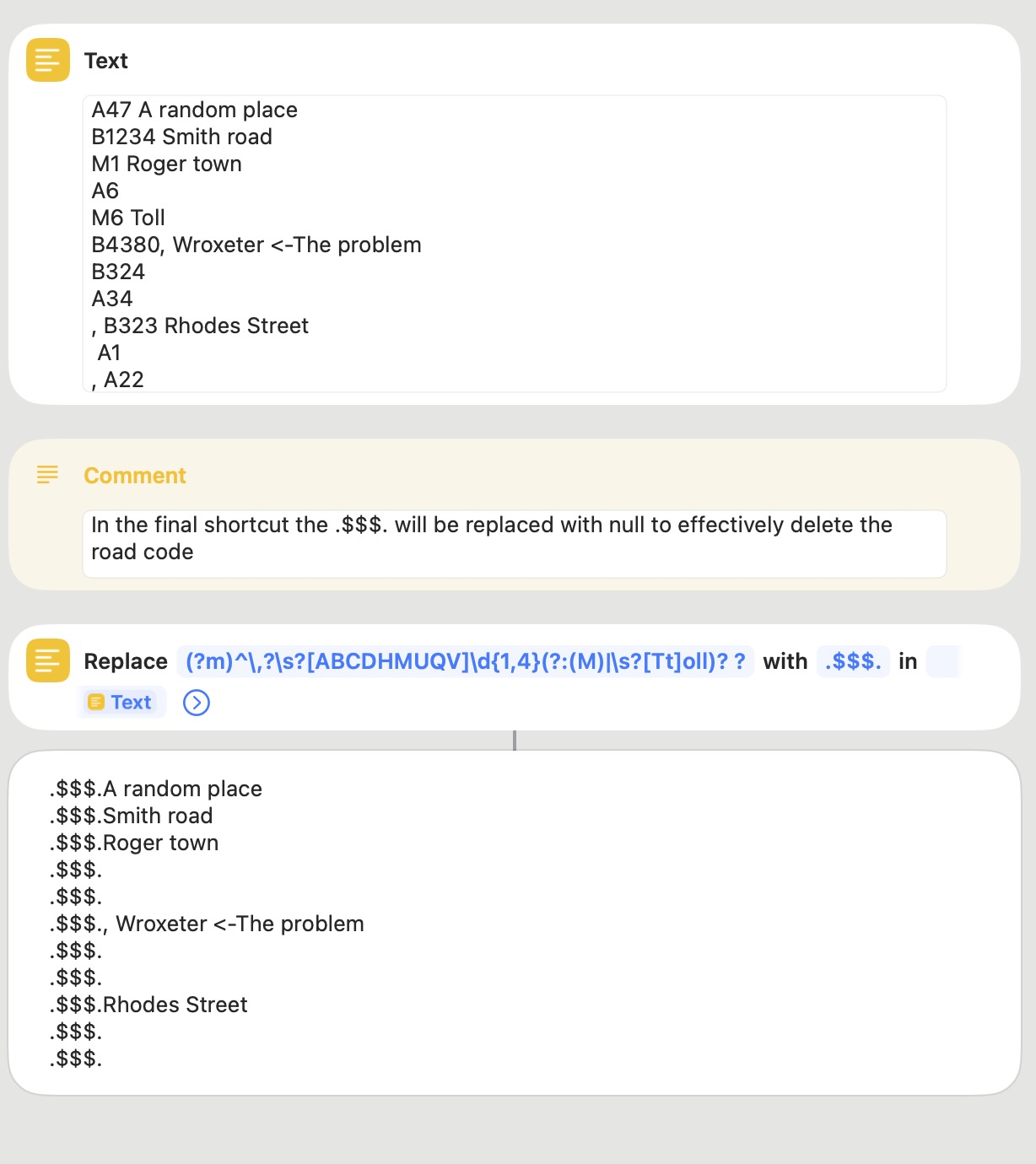
Just as a point of information, the \s metacharacter matches a space but also matches a tab and various line endings. In some instances these can be used interchangeably but not always.
I have inserted spaces in the text after M1, A34, and A1, and the following is the result with technomorph’s pattern:
I guess as I want to handle as per the second option? In reality, I’d actually be removing them completely so replacing with ‘null’.
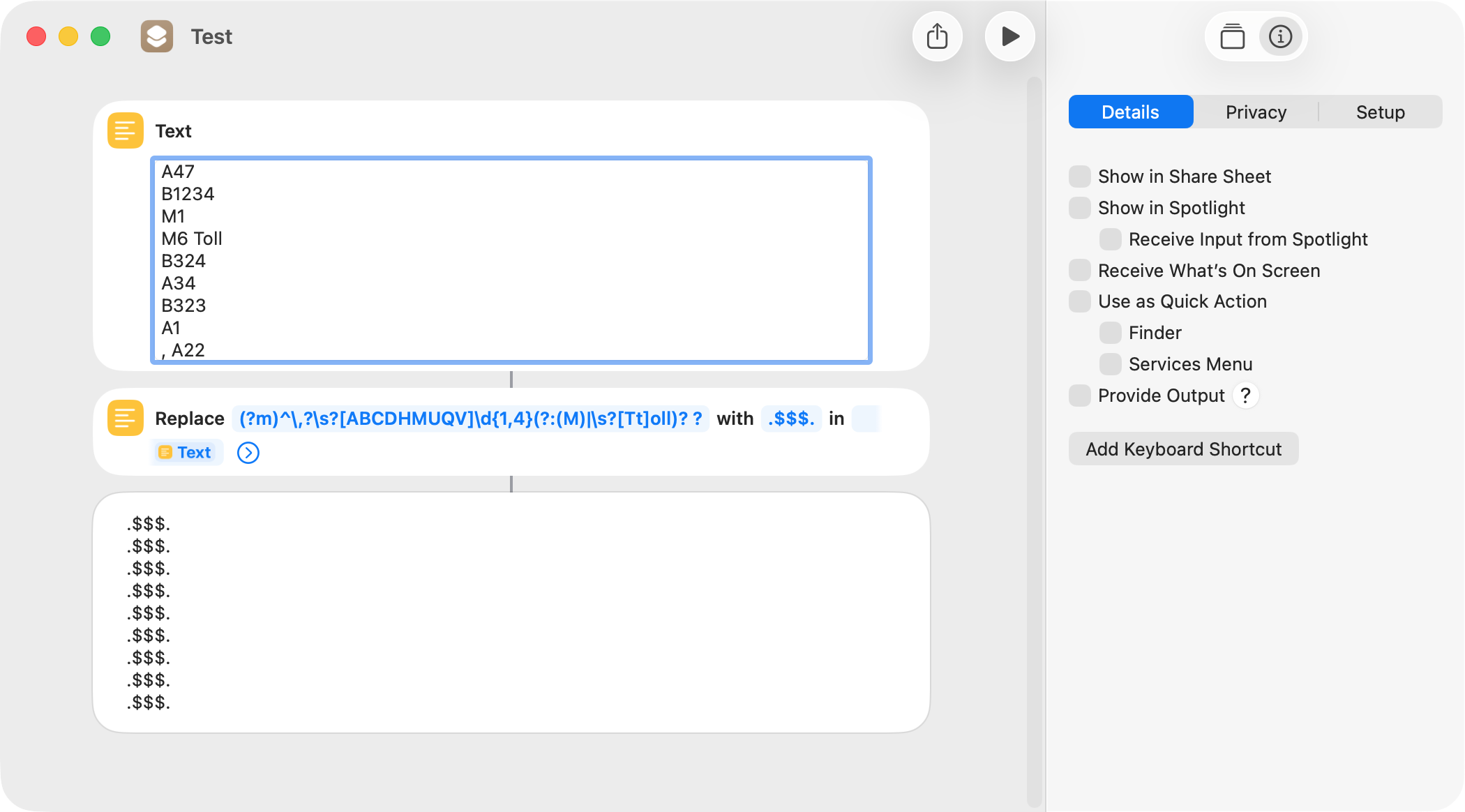
I’ve tried to copy out the suggested regex but I’m missing something as it’s not working with respect to removing the ‘Toll’ in Toll road designation. Also the preceding spaces are still in place.(as far as I can see - poor eyesight)
BTW, if a literal space is hard to see, you might consider using the \h horizontal whitespace metacharacter. Also, I don’t think you need to escape a comma.
You just need to add the comma to the end of the pattern just before the space. The horizontal whitespace metacharacter is easier to see then a literal space, so my suggestion would be:
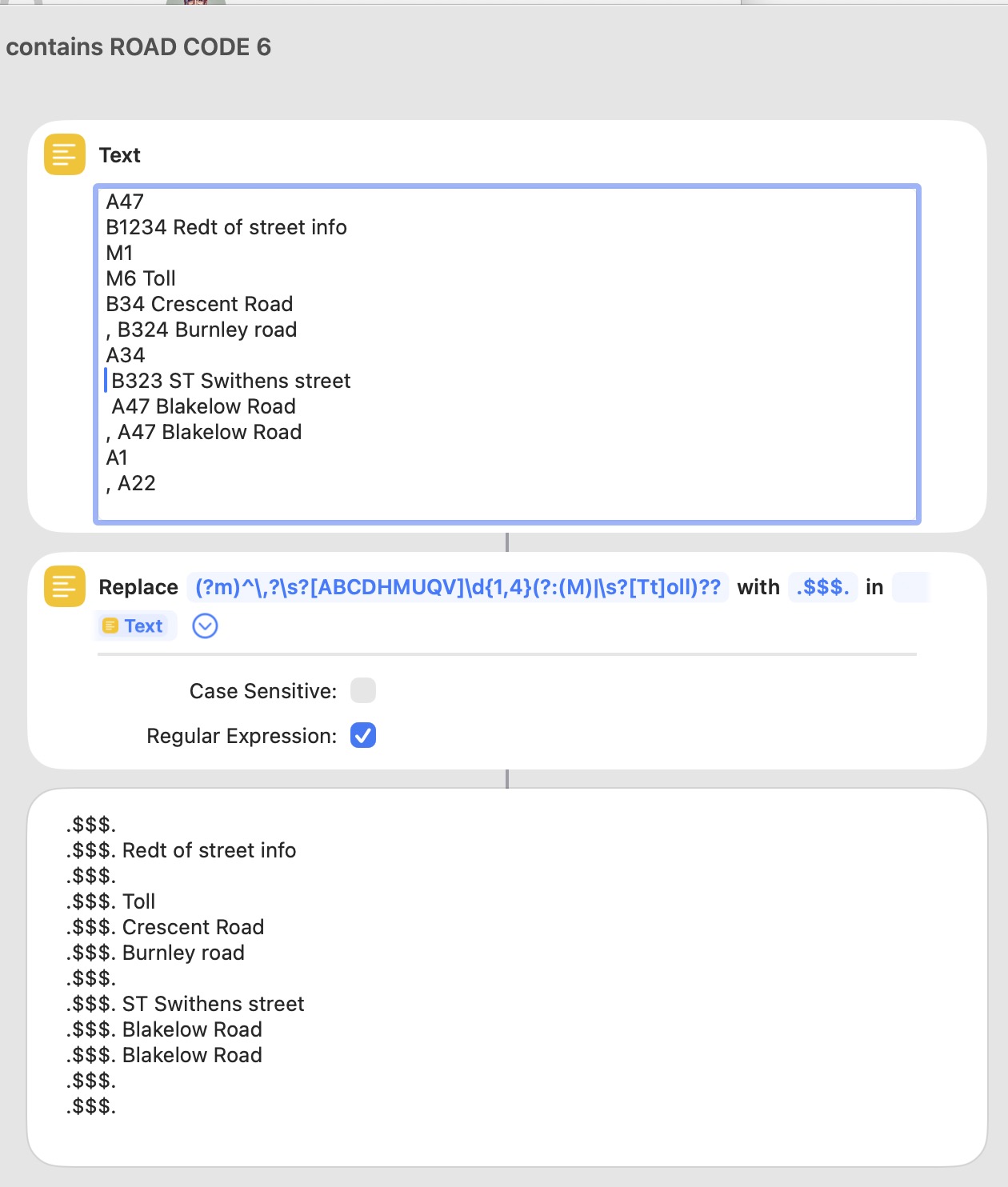
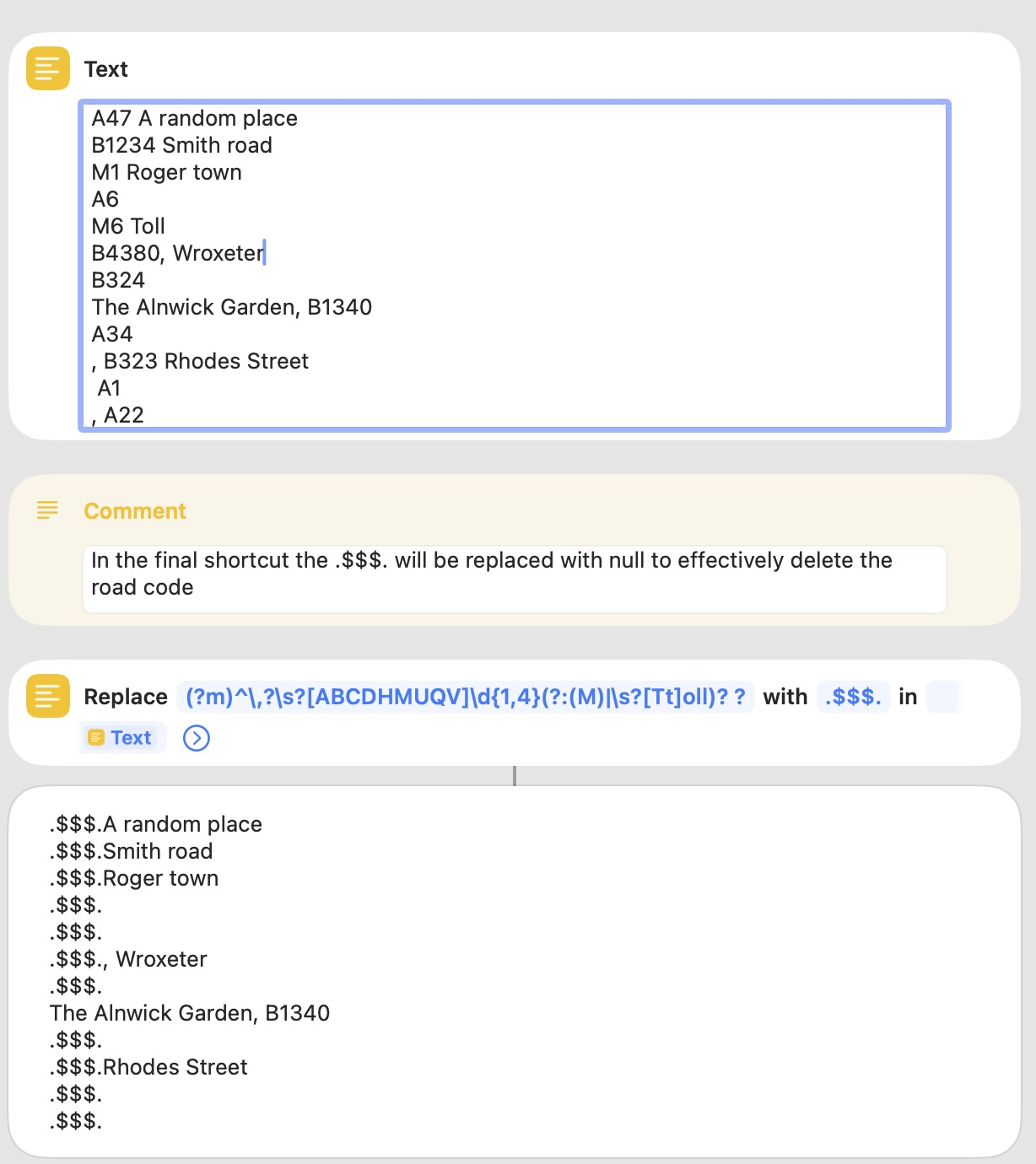
It may well forgetting about this, I’ve just come up with another ‘issue’ where the road name comes at the end of a Street as you can see here for the Alnwick Garden:
That might be a workable approach. The following is on a proof-of-concept basis, and it removes whitespace at the beginning and end of each line of the string, a comma followed by a whitespace within the string, and then uses Nigel’s regex pattern to remove the road codes. A Replace Text action only takes a few milliseconds to run, so having two such actions should not be a concern.
It could well indeed work but it’d still need to take care of roads like ‘The Alnwick Garden, B1340’ where the road code is at the end?
Is this possible?
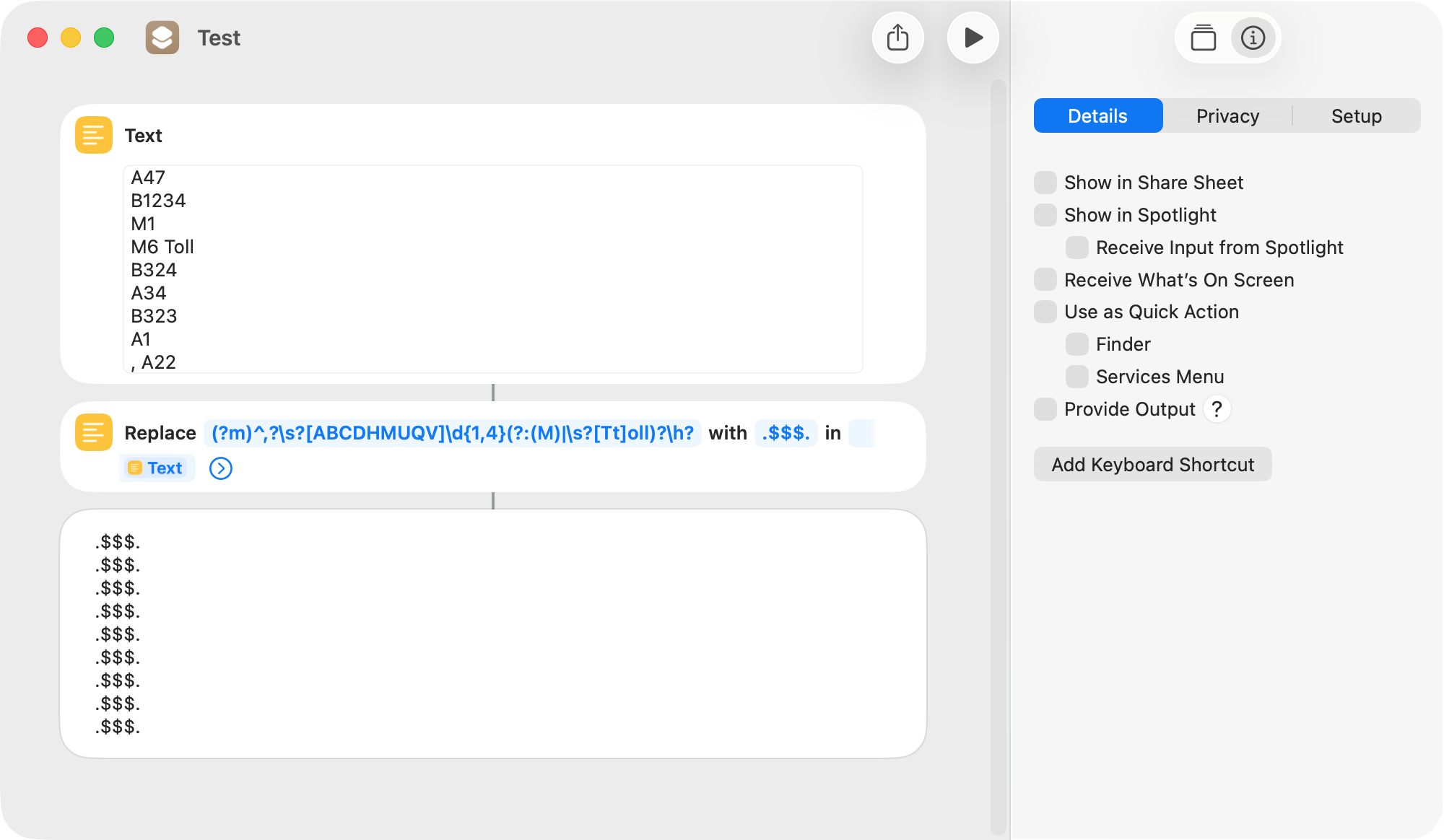
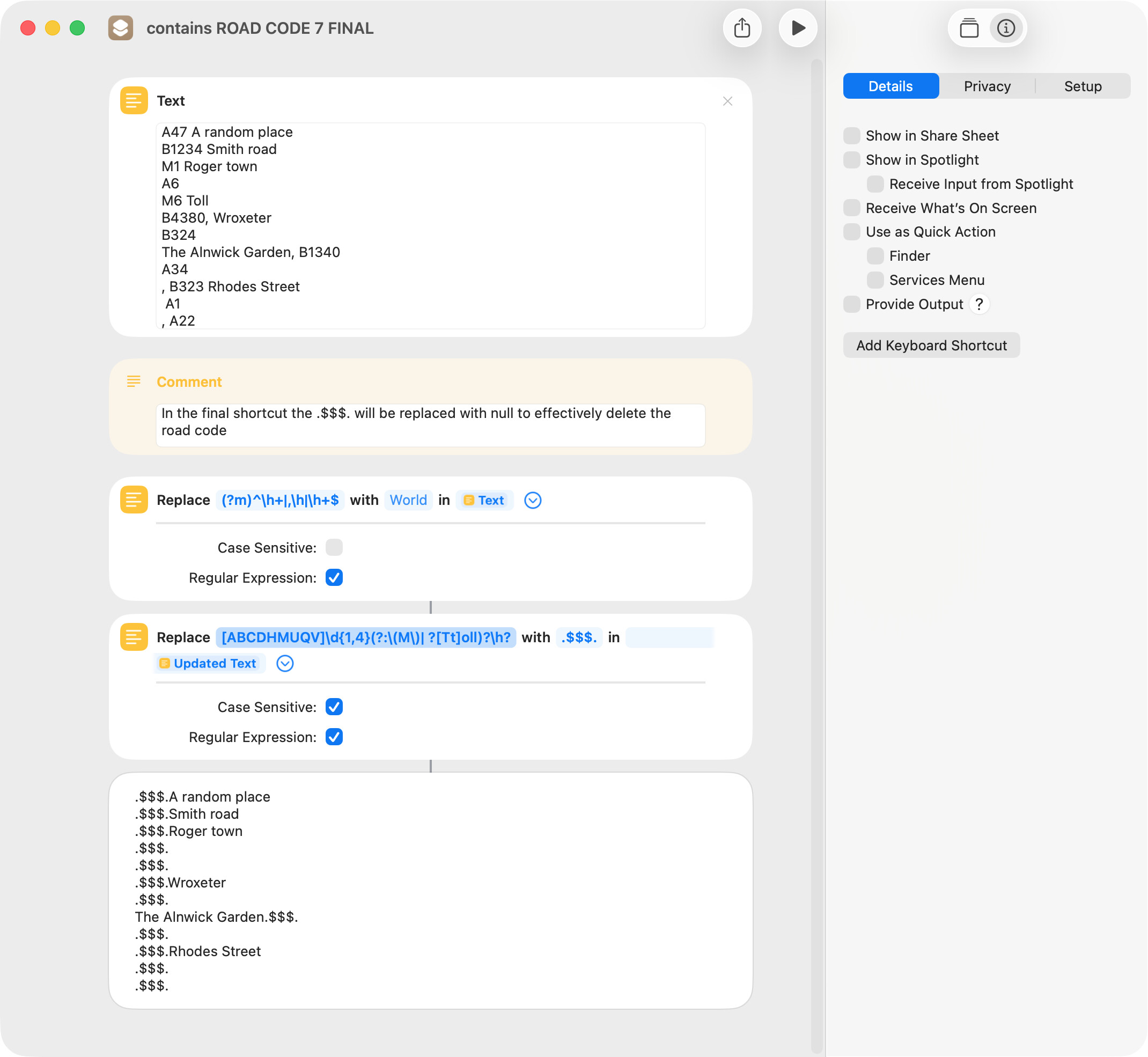
I downloaded and installed a fresh copy of the shortcut. It did remove B1340 from the end of The Alnick Garden and inserted .$$$. in its place. This can be seen in the screenshot above. I added another similar entry with the road code at the end, and it was also removed and replaced as expected.
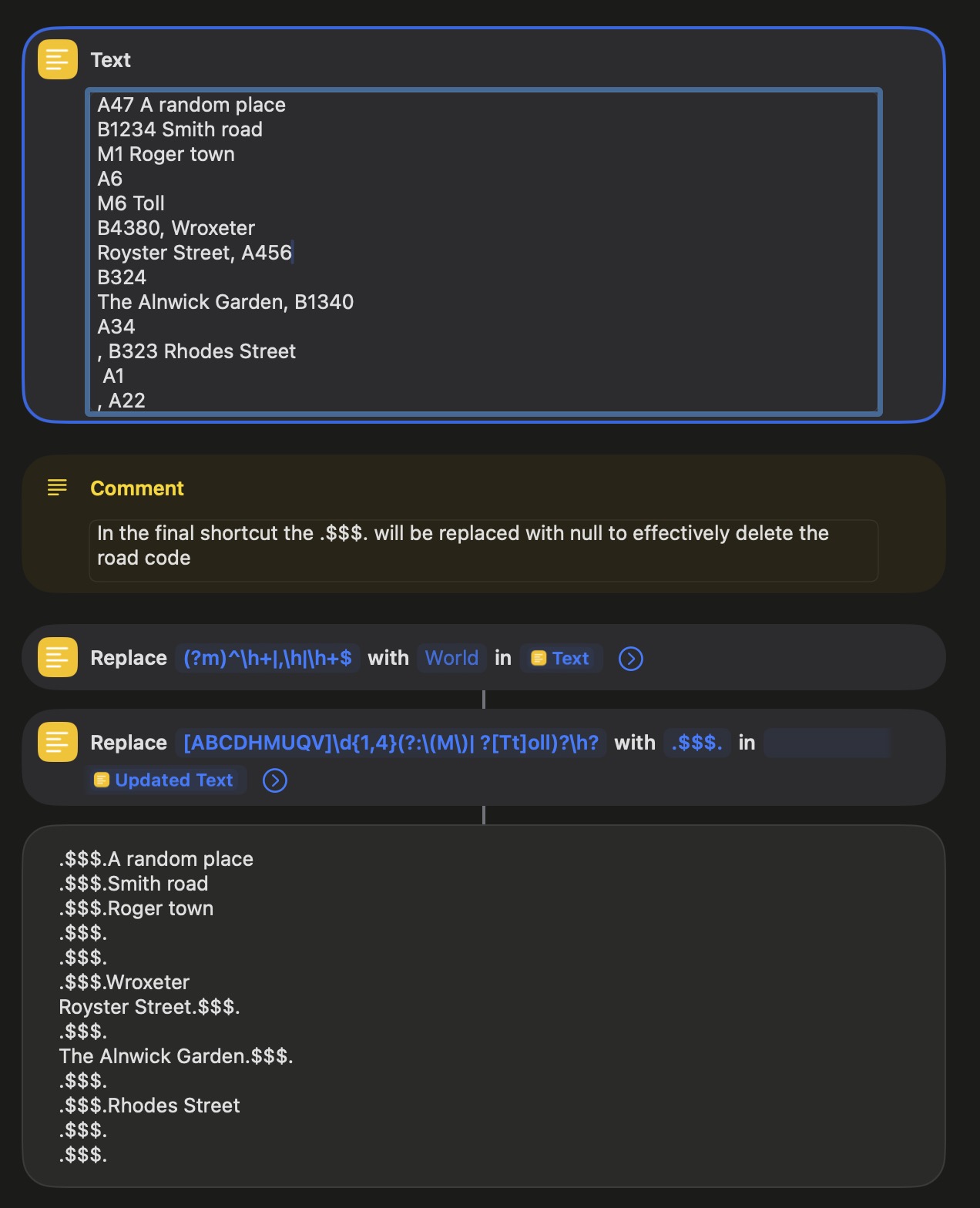
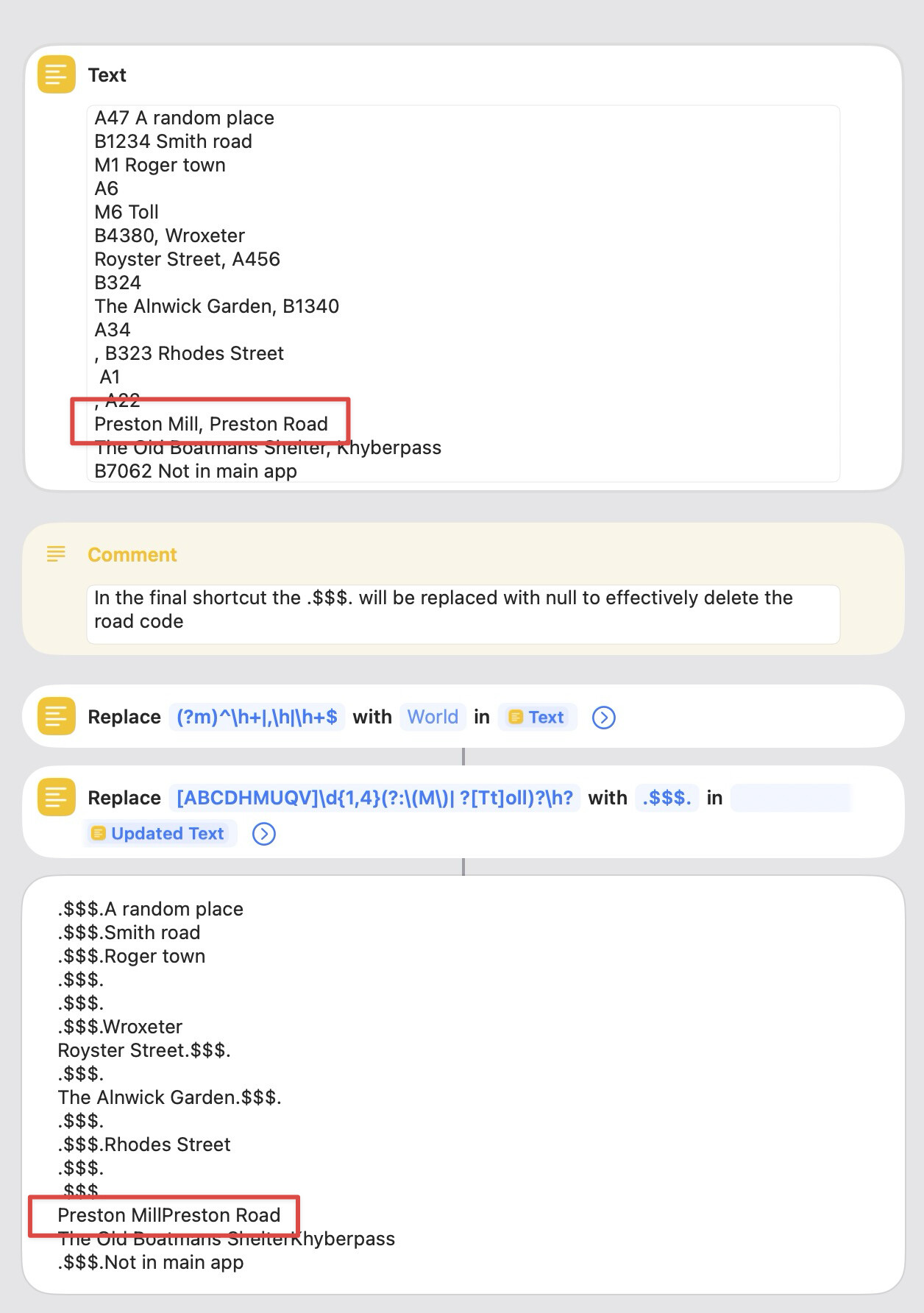
I put the new code in place today and noticed some weirdness. When run over a street of:
Preston Mill, Preston Road
It changed it to:
Preston MillPreston Road
That ism in addition to the ‘road code’ removal it seems to have stripped the ‘comma space’ out of it. I duplicated this in the revised test shortcut attached.
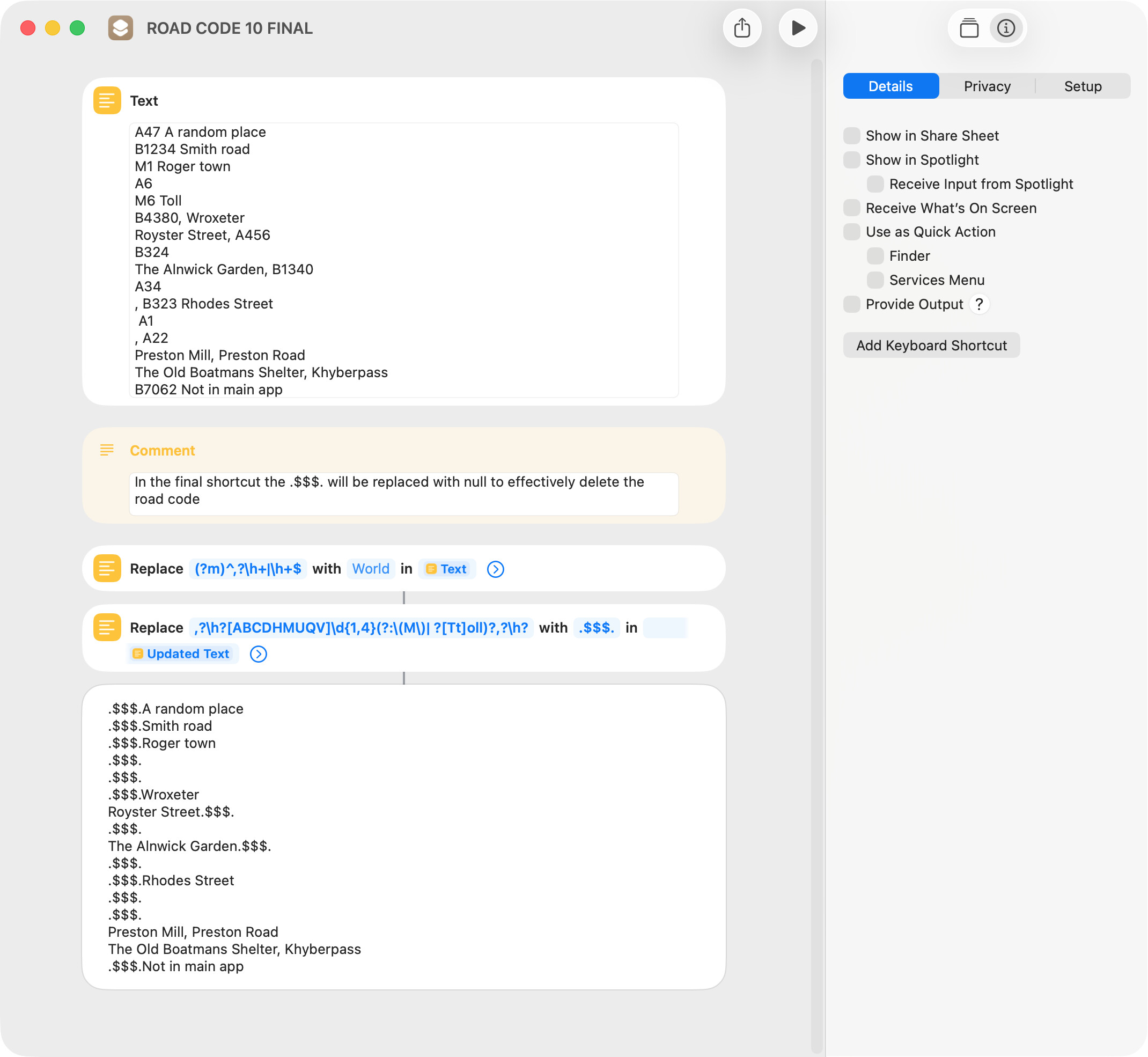
That happened because the first regex removed all instances of a comma followed by a space. I’ve edited the first regex to remove a comma-space only at the beginning of each line of the string. I also edited the second regex to remove a comma-space after a road name.
After testing the above, I found that a comma-space was left after retained text (like the Alnwick Garden), so I added a comma-space before the road name to the regex. Everything in the Text action now seems to work OK.
I use RegExKit all the time.
It allows you to work on your RegEx’s and see immediate results… lots of great hints and shows you what’s capturing etc. and code generation for different languages (I use PHP generation for AppleScript / Objective C as it escapes everything properly
This site is awesome for explaining more advanced topics and even simple ones
Also helpful for making your RegExs more efficient.