Using small scripts, I add optional personal information at the end of some file names (specifically, if they have already been viewed “ ”, if I consider them to be of bad quality “b. q”, or if I liked them “ ” and, if they exist, they appear in that order).
To get the icons to rearrange themselves in the default order when added, I wrote the script shown below (it trims the existing personal information at the end of the name and adds the sorted result of the new information, if necessary).
To simplify things, I have replaced the name of a file with text.
It works well, but I think the algorithm is very clumsy because it breaks down all possible cases one by one.
Furthermore, my approach is only suitable for adding a specific icon, so it would be necessary to write a similar script for each of the other two elements that can be added.
The goal is to find a more concise algorithm that does not break down the possible cases one by one and, if possible, is valid for any of the optional elements.
use AppleScript version "2.4"
use scripting additions
property one : " 🧐" -- Already seen
property two : " b. q" -- bad quality
property three : " 👍" -- OK
global nBasic
--If all optional elements are present, the preferred order is " 🧐 b. q 👍"}
--set nBasic to "This is the usual test 👍 🧐 b. q" -- TEST → → This is the usual test 🧐 b. q 👍
--set nBasic to "This is the usual test b. q" -- TEST → "This is the usual test 🧐 b. q"
--set nBasic to "This is the usual test 🧐" -- TEST → "This is the usual test 🧐"
-- etc.
set nBasic to "This is the usual test 👍 b. q"
set nBasic to addOne(nBasic)
display dialog "nBasic → " & nBasic -- TEST → This is the usual test 🧐 b. q 👍
on addOne(_nBasic)
if one is not in _nBasic then
if two is in _nBasic and three is in _nBasic then -- " b. q 👍" / " 👍 b. q"
return (text 1 thru -(((length of two) + (length of three)) + 1) of _nBasic) & one & two & three
end if
if two is in _nBasic then -- " b. q" --
return (text 1 thru -(((length of two)) + 1) of _nBasic) & one & two
end if
if three is in _nBasic then -- " 👍"
return (text 1 thru -(((length of three)) + 1) of _nBasic) & one & three
end if
if two is not in _nBasic and three is not in _nBasic then -- if there are none
set _nBasic to _nBasic & one
return _nBasic & one
end if
else -- one is in _nBasic -- " 🧐"
if two is in _nBasic and three is in _nBasic then -- " 🧐" & (" b. q 👍" / " 👍 b. q") (in any order) → " 🧐 b. q 👍"
return (text 1 thru -(((length of one) + (length of two) + (length of three)) + 1) of _nBasic) & one & two & three
end if
if two is in _nBasic then -- " 🧐" + " b. q" (in any order) → " 🧐 b. q"
return (text 1 thru -(((length of one) + (length of two)) + 1) of _nBasic) & one & two
end if
if three is in _nBasic then -- " 🧐" + " 👍" (in any order)
return (text 1 thru -(((length of one) + (length of three)) + 1) of _nBasic) & one & three
end if
if two is not in _nBasic and three is not in _nBasic then
return _nBasic
end if
end if
end addOne
At least replace the if - endif blocks with a if - else if - endif chain. The last else respectively doesn’t need a condition because it will be executed if the other conditions evaluate to false
on addOne(_nBasic)
if one is not in _nBasic then
if two is in _nBasic and three is in _nBasic then -- " b. q 👍" / " 👍 b. q"
return (text 1 thru -(((length of two) + (length of three)) + 1) of _nBasic) & one & two & three
else if two is in _nBasic then -- " b. q" --
return (text 1 thru -(((length of two)) + 1) of _nBasic) & one & two
else if three is in _nBasic then -- " 👍"
return (text 1 thru -(((length of three)) + 1) of _nBasic) & one & three
else
return _nBasic & one
end if
else -- one is in _nBasic -- " 🧐"
if two is in _nBasic and three is in _nBasic then -- " 🧐" & (" b. q 👍" / " 👍 b. q") (in any order) → " 🧐 b. q 👍"
return (text 1 thru -(((length of one) + (length of two) + (length of three)) + 1) of _nBasic) & one & two & three
else if two is in _nBasic then -- " 🧐" + " b. q" (in any order) → " 🧐 b. q"
return (text 1 thru -(((length of one) + (length of two)) + 1) of _nBasic) & one & two
else if three is in _nBasic then -- " 🧐" + " 👍" (in any order)
return (text 1 thru -(((length of one) + (length of three)) + 1) of _nBasic) & one & three
else
return _nBasic
end if
end if
end addOne
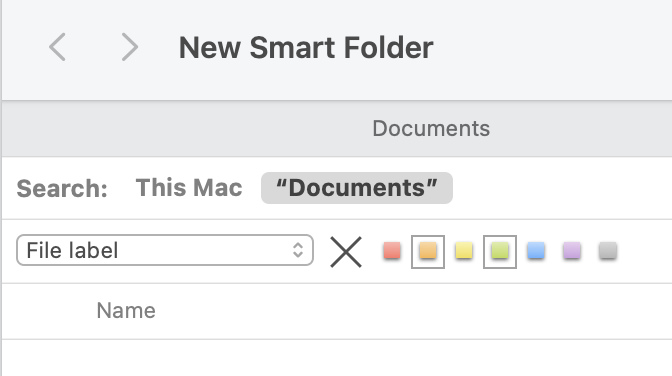
Consider to use tags or labels for this kind of annotations. You can add custom labels. One benefit is you can create smart folders to show the items dynamically.
First of all, thank you very much, StefanK, for your willingness to help me.
The code for the endless “if” blocks has been simplified somewhat with the use of “else if” after nesting the first condition. This will be useful for me in future scripts.
on addOne(_nBasic)
if one is not in _nBasic then
if two is in _nBasic and three is in _nBasic then -- " b. q 👍" / " 👍 b. q"
return (text 1 thru -(((length of two) + (length of three)) + 1) of _nBasic) & one & two & three
else if… (etc.)
I considered using your suggestion to use tags, but I rejected it because it is less visible than adding small elements at the end of the file name, and also because I was hoping to find an algorithm that would allow me to combine elements to achieve a certain order (I didn’t know how to do it, and the only thing I could think of was to cut part of the file name and then literally add the order of the manually sorted elements).
I would appreciate it if you could explain a little more about using smart folders to display items dynamically.
Suggestions are still pending for unifying addOne(_nBasic), addTwo(_nBasic), and addThree(_nBasic) into a single handler.
Thank you very much, StefanK, for showing me this new feature.
I avoid using tags; I prefer to use information that is in the file name.
As far as I can tell, if I understand correctly, it is equivalent to saving a search with the added feature that new items that meet the criteria specified in the filter will also be included in the search. In my case, I have not used tags, but rather " " OR " b. q" OR " " (from Finder, not from Spotlight).
It’s difficult to implement an universal algorithm, because there is no efficient/fast way to identify the information token(s). It would help for example to specify a unique separator between file name and tokens rather than a space character which can occur a dozen times in the file name.
If you know the range of the tokens in the file name you could create a handler to serialize them. For example 🧐 b. q becomes 01, then you can insert the index at the proper position, deserialize (convert) the indices back to the emojis/text equivalents and replace the token range with the new value.
This requires some coding effort but is likely more efficient than implementing three add... handlers.
e.g. “This is the usual test” (If “” OR “b. q” OR “” does not exist, add it to the end of the file name, adding the separator “-” when adding the first token) → “This is the usual test” ⇒ “This is the usual test - token1st”.
Once a token has been added, the separator will already exist and it will not be necessary to add it again.
No, 01 (as string) means it contains the first and second token (in almost all programming languages the first index of a sequence is zero). But it can be 12 instead of 01 because AppleScript’s first index is one.
The main problem with regard to efficiency is the amount of space characters. For a universal algorithm you need to separate This is the usual test and 👍 b. q to avoid the text 1 thru -(((length of two) + (length of three) spaghetti code. I recommend also to indicate the lack of a token with x to keep the position of the character, for example 🧐 👍 becomes 1x3
This is a staring point. It requires an underscore character between the file name and the tokens. It won’t work without it.
The script displays the source string, the token to add and the result
property one : "🧐" -- Already seen
property two : "b. q" -- bad quality
property three : "👍" -- OK
set nBasic to "This is the usual test_ 👍 b. q"
display dialog nBasic
set {baseText, serializedToken} to serializeBasic(nBasic)
set newIndex to "1"
display dialog "Will Add 🧐"
set newToken to addToken(serializedToken, newIndex)
set nBasicNew to baseText & "_" & deserializeBasic(newToken)
display dialog nBasicNew
on serializeBasic(theText)
set {saveTID, text item delimiters} to {text item delimiters, {"_"}}
set {base, tokens} to text items of theText
set AppleScript's text item delimiters to saveTID
set theIndex to ""
if tokens contains one then
set theIndex to theIndex & "1"
else
set theIndex to theIndex & "x"
end if
if tokens contains two then
set theIndex to theIndex & "2"
else
set theIndex to theIndex & "x"
end if
if tokens contains three then
set theIndex to theIndex & "3"
else
set theIndex to theIndex & "x"
end if
return {base, theIndex}
end serializeBasic
on deserializeBasic(theText)
set returnValue to ""
if theText contains "1" then set returnValue to returnValue & space & one
if theText contains "2" then set returnValue to returnValue & space & two
if theText contains "3" then set returnValue to returnValue & space & three
return returnValue
end deserializeBasic
on addToken(serializedToken, i)
if serializedToken contains i then return serializedToken
if i is "1" then
return i & text 2 thru 3 of serializedToken
else if i is "2" then
return text 1 of serializedToken & i & text 3 of serializedToken
else
return text 1 thru 2 of serializedToken & i
end if
end addToken
After reading your latest script, I realized that I misunderstood everything you were trying to explain to me.
Thanks to this latest script, (understanding it gave me a headache) but it was very satisfying to finally get it.
I can’t express how grateful I am for your time and effort.
I congratulate you for guiding me through your handlers until I understood it and all the learning that comes with it.
The results are amazing, achieving all the objectives.
All you need to do is change the value of
set newIndex to “1” to any other value
to make it valid for any token and make small changes so that the number of possible tokens can be expanded to as many as you want.
It’s wonderful.
Thank you very much, StefanK