Has anyone experienced this issue: Files with diacriticals in their names are returning an empty string when asking for their names.
tell application "Adobe Acrobat"
set docNames to (name of documents)
end
--> {"", "", "aaa.pdf", "bbb.pdf"} instead of {"ééé.pdf", "ààà.pdf", "aaa.pdf", "bbb.pdf"}
tell application "Adobe Acrobat"
set docNames to (file alias of documents)
repeat with i from 1 to length of docNames
set item i of docNames to word -1 of ((item i of docNames) as text)
end repeat
end tell
--> {"ééé.pdf"}
Since Japanese is my native language, I had never considered the possibility of filenames containing characters with diacritical marks — so this was completely new to me.
As a workaround, it seems that the name property of the PDF window can be used reliably.
# OS langage Japanese
#Acrobat Lang setting Japanese
tell application "Adobe Acrobat"
set listDoc to (name of every PDF Window) as list
log listDoc as list
--> {"ééé.pdf", "ààà.pdf"}
end tell
Also, there appears to be some variation in return values depending on Acrobat’s language setting.
In my environment, when both the OS and Acrobat are set to Japanese, the JavaScript return values were completely unusable.
# OS langage Japanese
#Acrobat Lang setting Japanese
tell application "Adobe Acrobat"
set listDoc to (name of every document) as list
log listDoc as list
--> {"e.e.e..pdf", "a.a.a..pdf"}
end tell
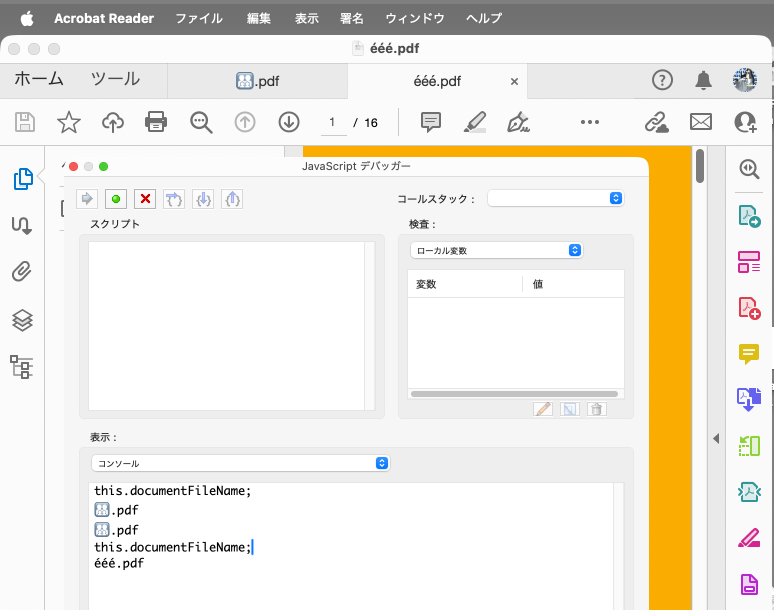
tell application "Adobe Acrobat"
set strFileName to (do script "this.documentFileName;") as text
log strFileName
(*....pdf*)
set strFileFullPath to (do script "this.path;") as text
log strFileFullPath
(*/Macintosh HD/Users/USERID/Desktop/a.a.a..pdf*)
#OR
(*/Macintosh HD/Users/USERID/Desktop/e.e.e..pdf*)
end tell
This is a bug I would never have encountered through my usual workflow, so moving forward, I’m thinking of exploring alternative ways to retrieve filenames and paths.
In the end, it turned out to be an Acrobat issue, but your post was very meaningful to me. Thank you so much!
Just a heads-up for anyone using Acrobat’s JavaScript API, especially the this.addWatermarkFromText() method:
There’s a long-standing bug (going back as far as Acrobat v10 or earlier) when using non-Latin characters — particularly Japanese fonts. When passing Unicode characters to addWatermarkFromText, the 2-byte Unicode values seem to get swapped internally. That is, the high and low bytes are reversed, leading to completely incorrect characters being rendered in the watermark.
For example:
‘亜’ (U+4E9C) becomes U+9C4E = ‘鱎’
‘あ’ (U+3042) becomes U+4230 = ‘䈰’
‘A’ (U+0041) becomes U+4100 = ‘䄀’
It looks like a UTF-16 byte order issue — probably treating BE as LE or vice versa.
This bug has been around for over a decade and still hasn’t been addressed. If you’re seeing garbled characters in watermark text, especially with Japanese or other non-Latin scripts, this could be the reason.
It’s not a bug report, just sharing in case others run into similar issues.
I haven’t verified it yet, but it’s possible that the issue I’m seeing now might also be related to this same byte-swapping bug.
At that time, it was possible to get the file name from the PDF window.
But now, the situation has gotten pretty bad and there’s not much that can be done about it.
I’ll write down a workaround below.
#!/usr/bin/env osascript
----+----1----+----2----+-----3----+----4----+----5----+----6----+----7--
(*
macOS:26.1
CFBundleExecutable:AdobeReader DC
AdobeReader ShortVersion:24.005.20421
CFBundleExecutable:AdobeAcrobat SCA PRO
AdobeAcrobat ShortVersion:25.001.20841
CFBundleExecutable:AdobeAcrobat 2020
AdobeAcrobat ShortVersion:20.005.30803
Acrobatで開いているファイルは
The open file is
順番に開きますので最初のファイルがID3最後に開くファイルがID1です
Since it will be opened in order, the first file is ID3 and the last file to be opened is ID1
👨👩👧👦.pdf
👨👩👧👦: 1F468, 200D, 1F469, 200D, 1F467, 200D, 1F466
レッド.pdf (ド-->ト ゙)
ド: 30C8, 3099
ééé.pdf
é: 0065, 0301
3ファイル
3Files
AcrobatのjavascriptAPIを使った場合の回避方法は見つけられませんでした
I couldn't find a way to avoid using Acrobat's javascript API
*)
----+----1----+----2----+-----3----+----4----+----5----+----6----+----7--
use AppleScript version "2.8"
use scripting additions
#全てfront Windowのファイル名を戻します
#Return all front Window file names
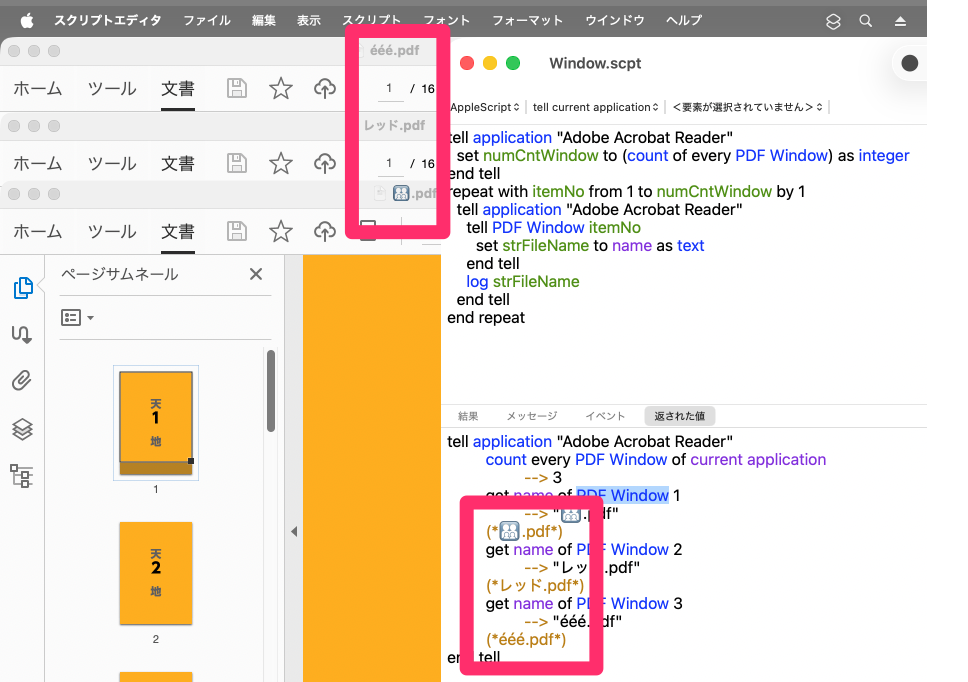
tell application "Adobe Acrobat Reader"
set listDoc to (name of every PDF Window) as list
log listDoc as list
--> {"ééé.pdf", "ééé.pdf", "ééé.pdf"}
(*ééé.pdf, ééé.pdf, ééé.pdf*)
end tell
-->NG
tell application "Adobe Acrobat Reader"
set numCntWindow to (count of every PDF Window) as integer
end tell
repeat with itemNo from 1 to numCntWindow by 1
tell application "Adobe Acrobat Reader"
tell PDF Window itemNo
activate
set strFileName to name as text
end tell
log strFileName
--> (*ééé.pdf*)
--> (*ééé.pdf*)
--> (*ééé.pdf*)
end tell
end repeat
-->NG
#documentでの取得
#日本語のNFD以外はNG
tell application "Adobe Acrobat Reader"
set numCntWindow to (count of every document) as integer
end tell
repeat with itemNo from 1 to numCntWindow by 1
tell application "Adobe Acrobat Reader"
tell document itemNo
activate
set strFileName to name as text
end tell
log strFileName
--> ............pdf<--NG
--> レッド.pdf <--OK
--> e.e.e..pdf<--NG
end tell
end repeat
-->NG
#回避策
#Workaround
tell application "Adobe Acrobat Reader"
set numCntWindow to (count of every document) as integer
end tell
repeat with itemNo from 1 to numCntWindow by 1
tell application "Adobe Acrobat Reader"
tell document itemNo
#Get file alias
set aliasFilePath to file alias as alias
end tell
end tell
#INFO FOR
set recordInfoFor to (info for aliasFilePath) as record
#FILENAME
set strFileName to (name of recordInfoFor) as text
log strFileName
end repeat
(*👨👩👧👦.pdf*)
(*レッド.pdf*)
(*ééé.pdf*)
-->OK
I hope this helps someone, even a little.♪
P.S.
After posting, I got curious and tested it with an older version — Adobe Reader 22.003.20314 —
but I got the same result.
It seems that getting the name of the specified ID from the PDF window doesn’t work,
and it might be due to macOS… though I don’t have any solid evidence for that.
P.S. 2
When using Acrobat’s JavaScript API from AppleScript, the problem occurs.
However, if you run the same script from the console or from a .js file,
the returned file name includes surrogates correctly and matches the visible characters.
P.S. 3
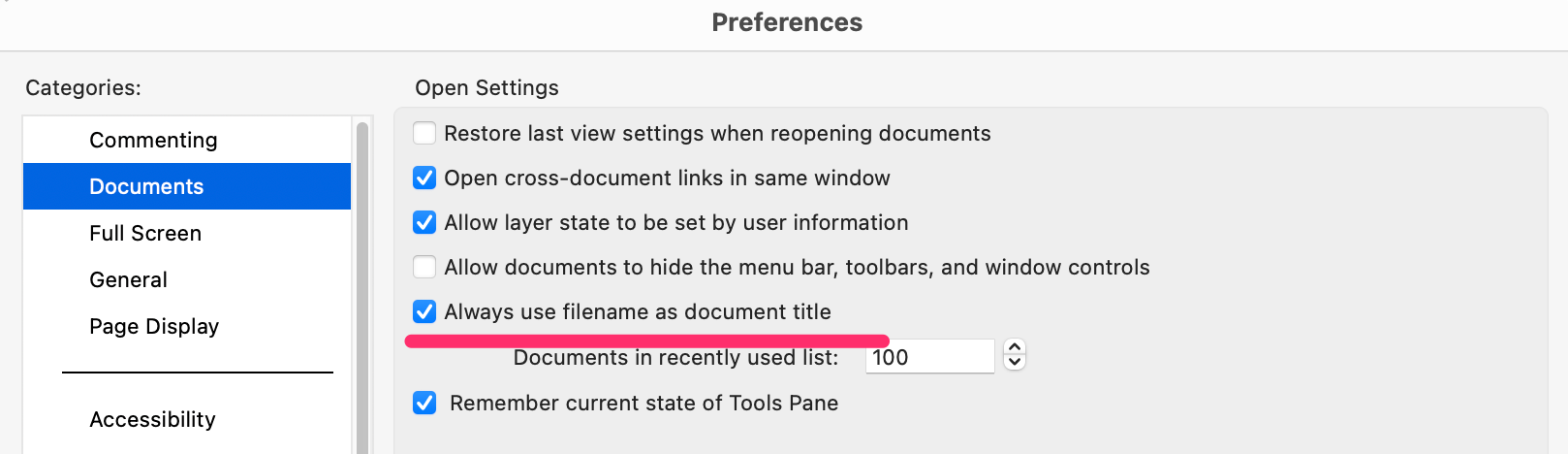
If you turn off the “Tab Display” option in the page display settings
and use the single-page display mode instead,
you can get the correct (visually accurate) file name from the PDF Window.
Same weirdness with an older Adobe Acrobat Pro.
As a workaround, you can extract the name from the document’s file alias property
tell application "Adobe Acrobat Pro"
{its version, name of 1st document, file alias of 1st document}
--> File name is "Catalogue Biesemeyer (pièces)-Avril 1994.pdf"
end tell
--> {"10.1.16", "", alias "Mojave:Users:jean:Documents:Mes Documents:Documentation:Outils:Biesemeyer:Catalogue Biesemeyer (pièces)-Avril 1994.pdf"}
Yes, that’s right.
I noticed something today — the title shown in the PDF Window actually depends on the settings.
There’s even an option to display the metadata title instead of the file name.
So for now, getting the file path from the document’s file alias seems to be the most reliable way.
Also, I found one more thing — this might be specific to Acrobat,
but when the “Tab View” setting is enabled and you open three PDFs, count of every window returns 3,
but properties of every UI element shows only one window.
(It makes sense, of course, since they’re tabs.)
So I’ll keep this in mind when working with applications that use tabbed windows.