I have a general regex question, which I’m testing on the regex101.com site. The text string is:
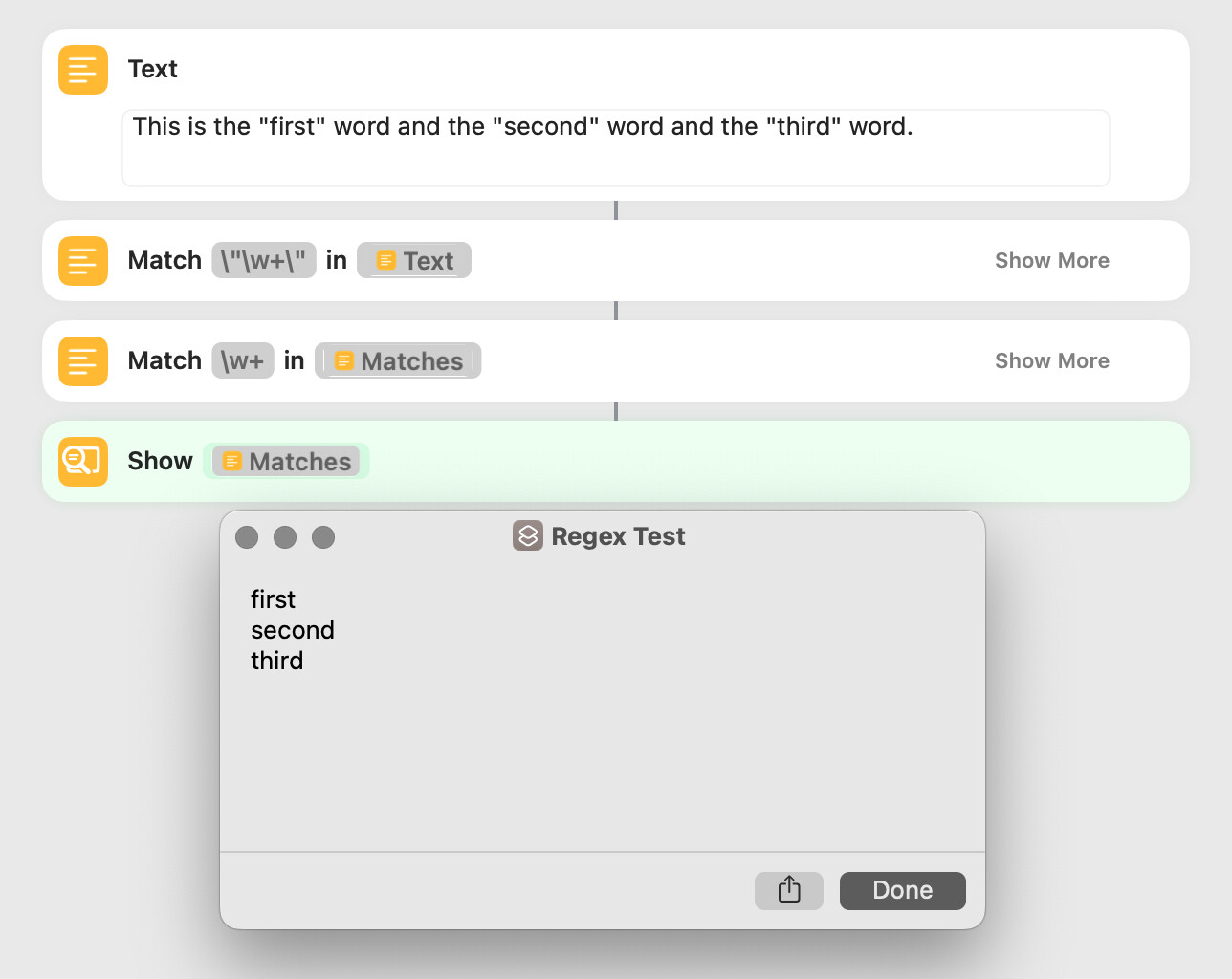
This is the "first" word and the "second" word and the "third" word.
My preliminary pattern–which generally works as I want but only returns the first match–is:
.*?\"(\w+?)\".*
The substitution is $1 (or perhaps $1\n).
I want the following to be returned. This is easily done without using a substitution, but I want to use a substitution (for learning purposes).
first
second
third
I’m not sure if this can be done, but my Google search appears to indicate that a possible solution is a non-capturing group inside a capturing group, but I couldn’t get that t work. Thanks?
It can depend a lot on the flavour of regex you’re using, what the source text may contain, and what you want to extract from it. If you’re using the Foundation framework’s ICU regex, Fredrik’s (sorry, ChatGPT’s ) suggestions are easy to handle and modify and are eminently sensible. A couple of reasonably nice direct regex replacement alternatives (again using ICU regex) might be:
use framework "Foundation"
use scripting additions
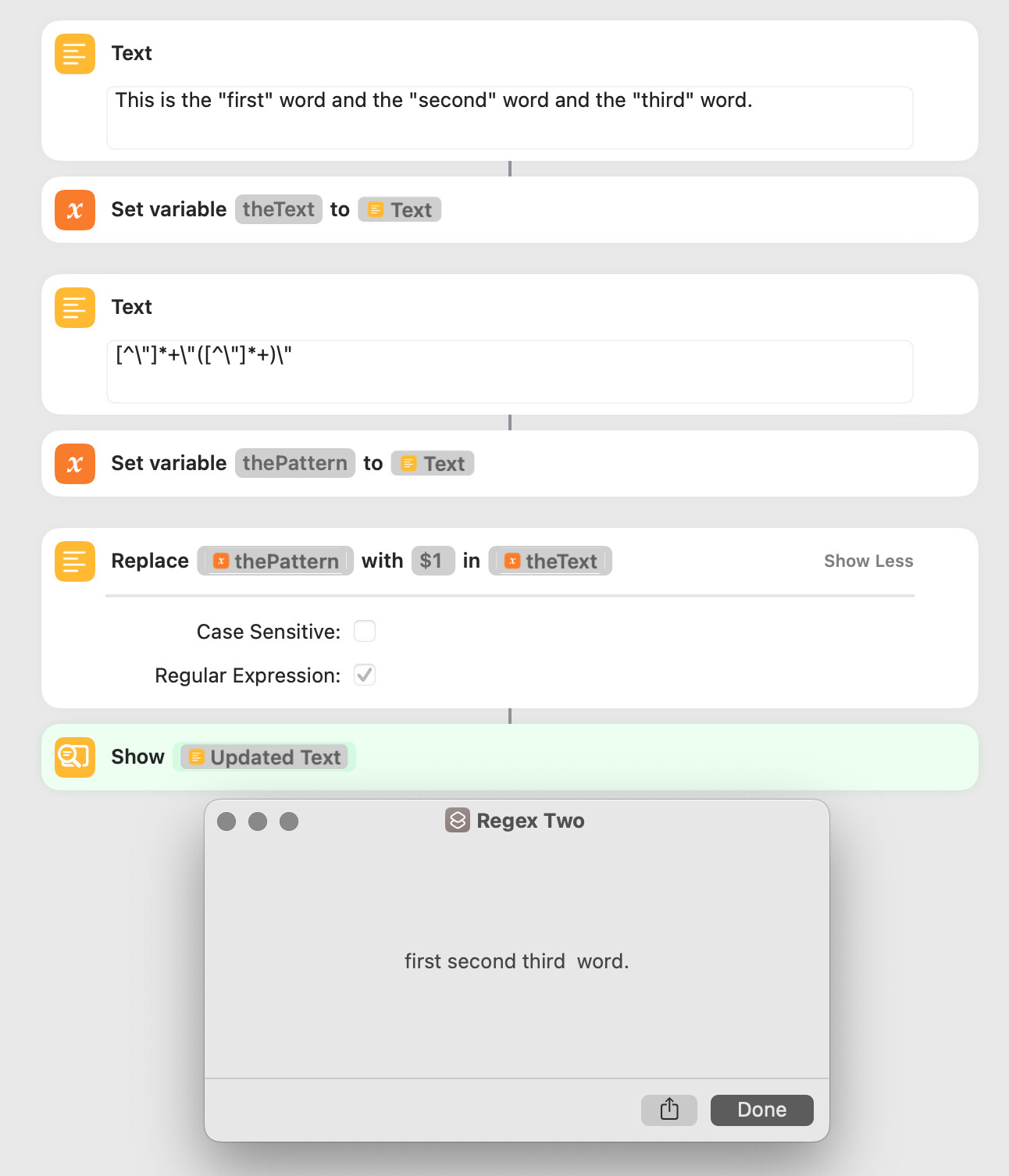
set theString to "This is the \"first\" word and the \"second\" word and the \"third\" word."
set theString to current application's NSString's stringWithString:theString
-- Replace every instance of an (optional) non-quoted section followed by a quoted section
-- with the contents of the quote and a linefeed.
theString's stringByReplacingOccurrencesOfString:("[^\"]*+\"([^\"]*+)\"") withString:("$1" & linefeed) ¬
options:(current application's NSRegularExpressionSearch) range:{0, theString's |length|()}
-- Lose everything after the third paragraph of the result.
(result as text)'s text 1 thru paragraph 3
Or:
use framework "Foundation"
use scripting additions
set theString to "This is the \"first\" word and the \"second\" word and the \"third\" word."
set theString to current application's NSString's stringWithString:theString
-- Replace the entire string with the contents of the first three quotes separated by linefeeds
theString's stringByReplacingOccurrencesOfString:("(?s)[^\"]*+\"([^\"]*+)\"[^\"]*+\"([^\"]*+)\"[^\"]*+\"([^\"]*+)\".*+") ¬
withString:("$1" & linefeed & "$2" & linefeed & "$3") ¬
options:(current application's NSRegularExpressionSearch) range:{0, theString's |length|()}
return result as text
Thanks Nigel for the response. My initial post was poor in that it did not state that my test vehicle was a shortcut. I made this omission with the aim of simplifying my request, but it had the opposite result.
Anyways, as stated in my initial post, the simple answer to my request appears to be not to use a substitution:
However, for learning purposes, I was interested by your first suggestion, which uses a substitution (as I want) and works as expected in a shortcut. For some reason, a linefeed can not be used in the substitution, so I used a space instead. Also, the end of the returned text needs to be removed, but that’s easily done.
"*+" is an optimisation of "*". It’s supported by ICU regex and several other regex “flavours” and happens to be usable here. It means (to quote from the ICU page): “Match 0 or more times. Match as many times as possible when first encountered, do not retry with fewer even if overall match fails (Possessive Match).” (My italics.)
For instance, if you have the string "This contains \"quoted\" text." and are unwise enough use the pattern ".*\"(.*)\".*" to extract the text between the quotes, the result will indeed be "quoted". But each instance of ".*" will have caused a search to the end of the the source text, because "." also matches the quote charcters. The regex engine will have had to do a series of windings-back to try and find an explicit match to the full pattern involving both quote characters. The "*" mechanism drops breadcrumbs for such windings-back even though they may turn out in the end not to be needed. The "*+" version neither drops breadcrumbs nor winds back and is thus faster. But everything it matches counts towards whether or not the full pattern matches.
The pattern in my first script matches every non-quote character (if any) up to a quote, the quote character itself, every non-quote up to the next quote, and that quote character. The non-quotes between the two quotes are in a capture group that’s matched by the “$1” in the replacement string. In a stringByReplacingOccurrencesOfString: … context, the pattern’s matched as many times as it occurs in the source string, each new search beginning at the character after the current match.
The text after the last quote character isn’t matched, and there could perhaps be more than three quoted sections in the source, which would all be matched, so the result has to be trimmed. Straight AppleScript was the easiest solution here.
Yeah. Some regex features and concepts can be difficult to grasp. But I didn’t make it any easier by failing to specify exactly what "*+" is an optimsation of! Apologies for this. Glad you managed to understand despite the omission. I’ve now attempted to improve the explanation above.
You’re right. Because of the way I initially thought to tackle the problem, I was still thinking in terms of getting the first three. But your suggestion makes more sense when getting the contents of all of an unknown number quotes (as long as there’s at least one!).